- SELECT * FROM Customers;
- SELECT * FROM Customers WHERE city LIKE='K%'; ( _ - один символ; [!a-c] - не начинается с "а b c";)
- SELECT * FROM Customers WHERE city IN ('Kovel', 'London');
- SELECT * FROM Customers WHERE price BETWEEN 10 AND 20; (включительно)
- SELECT DISTINCT country FROM Customers;
- SELECT * FROM Customers WHERE country IS NOT NULL;
- SELECT * FROM Customers WHERE country='Germany' AND NOT city='Berlin';
- SELECT * FROM Customers WHERE country='Ukraine' OR country='Italy';
- SELECT * FROM Customers ORDER BY country DESC, customerName ASC; //default ASC
- INSERT INTO Customers (customerName, country) VALUES ('Max', 'Ukraine');
- UPDATE SET Customers customerName='Max', country='Ukraine' WHERE city='Kovel'; (если не будет WHERE, то обновит тупо все записи)
- DELETE FROM Customers WHERE customerName='Max';
- SELECT CustomerName, Address+', '+City+', '+PostalCode+', '+Country AS Address FROM Customers AS MyTable;
- INNER JOIN: Returns all rows when there is at least one match in BOTH tables
- LEFT JOIN: Return all rows from the left table, and the matched rows from the right table
- RIGHT JOIN: Return all rows from the right table, and the matched rows from the left table
- FULL JOIN: Return all rows when there is a match in ONE of the tables (даже если не будет совпадений, выведет все)
- CROSS JOIN:
SELECT * FROM table1 CROSS JOIN table2;
или
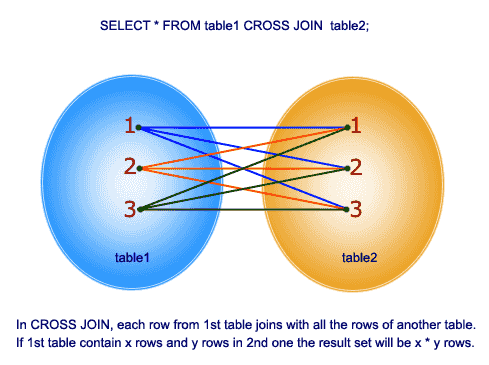
Если добавить условие, то будет работать как обычный JOIN (INNER JOIN)
SELECT * FROM Customers INNER JOIN Orders ON Customers.city=Orders.city;
SELECT * FROM Customers INNER JOIN Orders ON Customers.city=Orders.city;
SELECT * FROM Customers LEFT JOIN Orders ON Customers.CustomerID=Orders.CustomerID;
SELECT City, Country FROM Customers
WHERE Country='Germany'
UNION ALL
SELECT City, Country FROM Suppliers
WHERE Country='Germany'
ORDER BY City;
Если без ALL, то не будут выводиться города дубликаты. Запросы должны иметь равное количество столбцов.
SELECT * INTO CustomersBackup2013 IN 'Backup.mdb' FROM Customers; - внешнюю базу можно не указывать. Копирует данные из одной таблицы в другую НОВУЮ.
Аналог SELECT INTO, только данные копирует в уже существующую таблицу.
INSERT INTO Customers (CustomerName, Country) SELECT SupplierName, Country FROM Suppliers WHERE Country='Germany';
CREATE DATABASE my_db;
CREATE TABLE Persons
(
P_Id int NOT NULL CHECK (P_Id>0),
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (P_Id)
FOREIGN KEY (P_Id) REFERENCES Persons(P_Id)
);
ALTER TABLE Persons DROP PRIMARY KEY;
CREATE INDEX PIndex ON Persons (LastName); - создает индекс. Ускоряет работу поисковых запросов, но замедляет работу вставки и обновления. Indexes allow the database application to find data fast; without reading the whole table.
TRUNCATE TABLE table_name; - удаляет данные внутри таблицы.
DROP TABLE table_name; - удаляет таблицу.
ALTER TABLE Persons DROP COLUMN DateOfBirth;
ALTER TABLE Persons ALTER COLUMN DateOfBirth year;
ALTER TABLE Persons ADD COLUMN DateOfBirth date;
CREATE VIEW view_name AS SELECT column_name(s) FROM table_name
WHERE condition
SELECT * FROM [Current Product List]
SELECT City, Country FROM Customers
WHERE Country='Germany'
UNION ALL
SELECT City, Country FROM Suppliers
WHERE Country='Germany'
ORDER BY City;
Если без ALL, то не будут выводиться города дубликаты. Запросы должны иметь равное количество столбцов.
SELECT * INTO CustomersBackup2013 IN 'Backup.mdb' FROM Customers; - внешнюю базу можно не указывать. Копирует данные из одной таблицы в другую НОВУЮ.
Аналог SELECT INTO, только данные копирует в уже существующую таблицу.
INSERT INTO Customers (CustomerName, Country) SELECT SupplierName, Country FROM Suppliers WHERE Country='Germany';
CREATE DATABASE my_db;
CREATE TABLE Persons
(
P_Id int NOT NULL CHECK (P_Id>0),
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (P_Id)
FOREIGN KEY (P_Id) REFERENCES Persons(P_Id)
);
ALTER TABLE Persons DROP PRIMARY KEY;
CREATE INDEX PIndex ON Persons (LastName); - создает индекс. Ускоряет работу поисковых запросов, но замедляет работу вставки и обновления. Indexes allow the database application to find data fast; without reading the whole table.
TRUNCATE TABLE table_name; - удаляет данные внутри таблицы.
DROP TABLE table_name; - удаляет таблицу.
ALTER TABLE Persons DROP COLUMN DateOfBirth;
ALTER TABLE Persons ALTER COLUMN DateOfBirth year;
ALTER TABLE Persons ADD COLUMN DateOfBirth date;
CREATE VIEW view_name AS SELECT column_name(s) FROM table_name
WHERE condition
SELECT * FROM [Current Product List]
Преимущества использования представлений:
- Дает возможность гибкой настройки прав доступа к данным за счет того, что права даются не на таблицу, а на представление. Это очень удобно в случае если пользователю нужно дать права на отдельные строки таблицы или возможность получения не самих данных, а результата каких-то действий над ними.
- Позволяет разделить логику хранения данных и программного обеспечения. Можно менять структуру данных, не затрагивая программный код, нужно лишь создать представления, аналогичные таблицам, к которым раньше обращались приложения. Это очень удобно когда нет возможности изменить программный код или к одной базе данных обращаются несколько приложений с различными требованиями к структуре данных.
- Удобство в использовании за счет автоматического выполнения таких действий как доступ к определенной части строк и/или столбцов, получение данных из нескольких таблиц и их преобразование с помощью различных функций.
Useful aggregate functions:
- AVG() - Returns the average value
- COUNT() - Returns the number of rows
- FIRST() - Returns the first value
- LAST() - Returns the last value
- MAX() - Returns the largest value
- MIN() - Returns the smallest value
- SUM() - Returns the sum
Useful scalar functions:
- UCASE() - Converts a field to upper case
- LCASE() - Converts a field to lower case
- MID() - Extract characters from a text field
- LEN() - Returns the length of a text field
- ROUND() - Rounds a numeric field to the number of decimals specified
- NOW() - Returns the current system date and time
- FORMAT() - Formats how a field is to be displayed
SELECT ProductName, Price FROM Products WHERE Price>(SELECT AVG(Price) FROM Products);
SELECT COUNT(DISTINCT column_name) FROM table_name;
SELECT column_name FROM table_name ORDER BY column_name DESC|ASC
LIMIT 1; - Аналог FIRST() LAST()
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
SELECT Employees.LastName, COUNT(Orders.OrderID) AS NumberOfOrders FROM (Orders
INNER JOIN Employees
ON Orders.EmployeeID=Employees.EmployeeID)
GROUP BY LastName
HAVING COUNT(Orders.OrderID) > 10;
INNER JOIN Employees
ON Orders.EmployeeID=Employees.EmployeeID)
GROUP BY LastName
HAVING COUNT(Orders.OrderID) > 10;
SELECT ProductName, ROUND(Price,1) AS RoundedPrice
FROM Products; - округляет и оставляет одну цифру после комы.
Комментариев нет:
Отправить комментарий